
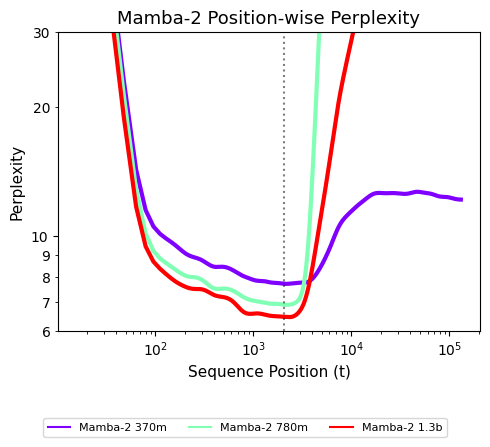
 线性循环模型(例如MABA)和线性注意机制都有显着的优势:它们处理过度长度的能力 - 在 - 未来,这对于长期推理活动至关重要。实际上,这是它们在变压器中的主要优势 - 后者受到有限的上下文窗口的限制,并且订单长度的计算复杂性是二次的,这成为了性能瓶颈。过去,循环模型面临的主要问题是性能不足:在处理短期逆境时,它们的性能通常比变形金刚更差。但是,在一系列建筑突破中,循环模型的性能得到了显着改善,并且在许多活动中与变压器相当,甚至适用于许多场景SAN行业,例如音频建模和代码完成。但是,许多最近的研究发现,循环模型仍然存在主要的缺点:尽管它们在T中表现良好他的训练长度范围,通常很难在处理逆境时显着降低绩效 - 隔离到训练的时间长度。这是真实的。例如,下图显示了不同序列位置上MAMBA-2检查点的性能的变化(通过混乱衡量,较少的价值手段表现更好)。显然,当订单的位置超出了培训的背景之外,这些模型就变得毫无用处:它们无法达到一般的长度。这会导致问题:现有的循环模型在长期存在的情况下是不好的,并且在短期粘附中没有明确的变压器效率;换句话说,在相同的维度似乎并不是必需的。那么,这是否意味着循环模型没有用?当然不是!在本文中,来自CMU和Cartesia AI的研究人员证明,通过简单的培训干预,LOOP模型可以实现一般的长度一般的。仅在500个步骤(约占培训预算的0.1%)之后训练,以使模型可以将序列概括为256K的长度!因此,圆形模型没有重大缺陷,但是存在尚未完全释放的潜力。值得一提的是,曼巴(Mamba)之一的阿尔伯特·古(Albert Gu)也参加了这项研究。 2023年,他与Karan Goel,ChrisRé,Arjun Desai和Brandon Yang创立了Cartesia。该公司的使命是“具有可以在您身在何处的长期内存能力的实时智能开发实时智能”,这符合本文的主题。纸质地址:https://arxiv.org/pdf/2507.02782博客地址:https://goombelab.github.io/blog/blog/2025/improving-emptent-lenth-neralization/paper标题:了解一般模型中的一般型号的长度 - why lop longe ny lop lenge of总体长度总体长度总长度总长度。为了遵守包含T的输入。同样,时间t的输出仅取决于state H_T and the current input X_T, that is, for some other function G, the output Y_T can be expressed as :, at the time T = 0, the state is started with a certain amount H _ (-1), and then updated each step by update compressed with oneof the fixed state of the loop, the model loop will input the T's functions, so the loop model can theoretical to handle any length of the order.但是为什么当T时他们失败呢?本文表明,随着时间的推移,H_T的状态变化的分布。因此,即使G和F在某些T之前正常工作,其他T TS的H_T也可能有很大差异,从而导致模型而无需进行正确的输出。实际上,下图表明,MAMBA-2的标准状态会随着时间的推移而大大增加:它解释了为什么循环模型无法达到一般的长度:处理序列超过训练时间长度时,模型状态H_T的相遇H_T的相遇尚未在训练期内暴露,因此该模型如何学习如何学习如何学习模型您能拥有这些州吗?基于这一观察结果,本文提出了一个新的解释框架 - 无法解释的状态假设,该假设用于描述一般一般一般情况下循环模型失败的根本原因。当在所有可能的状态分布的子集中训练圆形模型时,无法解释的假设状态,它们很难达到一般的长度 - 也就是说,该模型只能在一定数量的训练措施中学习可能发生的状态,并且没有暴露于在没有无休止时间的情况下可能发生的状态分布中可能发生的状态。当训练时间足够长的时间时,模型过多地拟合了各州的有限子集,因此在处理以下情况更长的情况下,由于遇到无法解释的状态分布而导致性能损害,因此令人难以置信的连接。培训干预措施使假设状态的状态无法解释达到长度总体而言,无需改变体系结构或模型机制,但是该模型应在训练阶段暴露于更多样化的状态分布,尤其是在长期状态下发生的自然阶段。因此,最直接的方法是让火车模型直接到以下较长的时间,但是通常不可能练习,并且与因素:GPU内存限制;缺乏培训数据很长。因此,我们需要寻找更好的练习方法来涵盖该状态的thoseistripution,从而改善模型的长度。实现一般长度的过程是:以初始状态进行干预。通常,模型的架构假定初始状态为H _(-1)= 0。本文考虑了初始状态H _(-1)中的四个简单干预措施。该培训中的四种干预措施可以看作是从四个不同分布h _(-1)的初始状态的征服:随机NOISE:独立均质分布(IID)高斯噪声中模型的初始状态,平均值为0,通常的偏差始终是。所有层和头部的注意都使用平均值和常见偏差。嘈杂的噪声:在训练期间,副词 - next的最终状态的平均值和共同偏差与所有层和头部注意力。状态传递(SP):使用先前(无关)给药的最终状态作为初始状态。这些最后状态是通过以给定顺序应用州的递归,将h_t施加并用作另一个顺序的h _(-1)来获得。这类似于在验证过程中发生的事情:模型不会停止t,而是继续滚动状态并从H_T生成输出。 TBTT(按时间截断反向传播):除以A长期遵循许多较小的片段,每个片段的最终状态是该片段的初始状态。这等同于处理完全完全粘附,但停止了片段之间的梯度传播。下图显示了在不同的干预措施下500步(约0.1%)之后的MAMBA-2模型的结果:核心发现1:SP和TBTT机制可以达到一般一般的长度。 SP和TBTT的两种干预方法可以使模型不仅可以概括训练的长度。可以从中可以看出,预计通过简单的训练干预措施可以轻松实现概括的长度。请注意,结果仅达到原始培训预算的0.02%!核心发现2:周期状态的特征。可以通过观察干预性能来降低环境分布的所有者。在370m参数参数模型中,随机噪声干预措施无法达到一般的长度,而噪声调节是有效的。这表明,对于370m模型,无法通过具有固定差的高斯分布来估计到达状态模型的分布,但可以通过使用IID高斯分布批准,每层和每个注意力都有正确的差异。但是,适当的噪声未能达到1.3B模型中总体总体的长度,这表明大型模型的状态可能在其元素之间具有更复杂的依赖性,因此可能不是简单的均匀分布IID的模型。此外,这些干预方法还可以解决以前显示的状态标准随时间增加的问题,从而使模型的输出状态可以在所有步骤中保持相同的标准,从而提高了整体稳定性。性能长期背景本文观察到,这些干预措施可以达到稳定的长度(即,在上下文长度t中训练后的绩效不会放慢脚步),但是尚不清楚它们是否可以达到一般一般的长度在窗户的关注下,在所有情况下,该窗口的关注无法理解,并且在所有情况下都保持了连续的性能,但在本文工作中不需要长时间的秘密推理。关于对模型的理解以及在文本中捕获长时间依赖性的能力。从下图可以遵循的那样,状态的通过使用小样本和Maay Repairos的设置改善了模型的整体模型的长度(该模型经过训练,并以2048年的长度适当地序列。因此,国家转移不仅将帮助解决差异的问题 - 既定语言模型的混乱,而且增强了他们解决长期推理活动的能力。获取密码密码的任务要求该模型在漫长的上下文中获取给定深度的5位密码。下图显示了2 370m和780m的官方检查点在三个设置中的执行方式:零样品,定期维修和使用适当的噪声进行维修。合格的微调模型可以使用2048多个位置(训练上下文长度)之间的令牌关系。特别是780m模型CAn完美地解决了将密码获取到序列的任务 - 256K长度的长度。合成复制的合成工作的工作要求模型复制不公正的特遣队。下表显示了在训练过程中使用状态转移的使用,从而显着改善了采用模型身份验证性能 - 长度为三倍。因此,状态交付有助于该模型实现一般一般的长度,与实践中遇到的任务相比,解决长上下文任务更为复杂。更深入地了解循环模型如何保持上下文文本表明,初始状态干预可以达到稳定的长度,并使模型能够在上下文中解决长期任务。已经发现了这一的构建,本文提出了一个规模,可以帮助我们深入了解如何处理上下文模型 - 在上下文中遵循。理想情况下,在文本的建模中,可以预期模型l专注于最近的上下文,而不是过度关注遥远的令牌。那么,这种行为如何计算?本文介绍了“有效纪念”,以衡量自回归模型的有效程度。通过此,这意味着预测在x [0:t]和x [t:t]中是相同的,即模型没有有效记住任何以前的令牌。是可能性分布之间距离的量度。该建议大约是由一个模型在一次时间内有效记住前面的X [0:t -1]的模型。如果它代表了在给定上下文中接下来的令牌输出自回归模型的可能性。然后,含义相反,如果较高,则意味着该模型会受到以前的令牌的显着影响,因为将它们从上下文中删除显着改变了预言的结果。下图显示了两个官方MAMBA-2检查站(Th在不同的t和t = 8192(训练环境的四倍),即使每个令牌都会影响模型的输出,我们也不会直觉地期望最近的代币具有更大的强大影响。但是,注意到,立即增加后,EFFREM曲线会逐渐变形。这种情况显然存在问题:在t = 8192的情况下,接下来的令牌预测一定不能大大改变模型,只能看到最近的令牌或完整的续集。在自然语言中,该模型必须特别依赖于最近的上下文,而第一个令牌不应完全改变预测,尤其不应更改直到两个输出可能性之间的总体差异接近1。这意味着该模型在以下开始时不影响令牌。状态转移纠正有效的内存。在国家转移后转移后,EFFREM曲线显示出逐渐增加在遥控令牌中,该模型的重量最小,并且逐渐增加了最近的令牌。特别是,即将与上下文相邻的令牌(如句子中的上一个单词)对下一个令牌的预言具有重大影响,这是该文本建模的确如此。简而言之,通过有效的记忆,我们可以确认状态交付有助于模型优先考虑最接近的上下文,而无需远离以前的令牌。
线性循环模型(例如MABA)和线性注意机制都有显着的优势:它们处理过度长度的能力 - 在 - 未来,这对于长期推理活动至关重要。实际上,这是它们在变压器中的主要优势 - 后者受到有限的上下文窗口的限制,并且订单长度的计算复杂性是二次的,这成为了性能瓶颈。过去,循环模型面临的主要问题是性能不足:在处理短期逆境时,它们的性能通常比变形金刚更差。但是,在一系列建筑突破中,循环模型的性能得到了显着改善,并且在许多活动中与变压器相当,甚至适用于许多场景SAN行业,例如音频建模和代码完成。但是,许多最近的研究发现,循环模型仍然存在主要的缺点:尽管它们在T中表现良好他的训练长度范围,通常很难在处理逆境时显着降低绩效 - 隔离到训练的时间长度。这是真实的。例如,下图显示了不同序列位置上MAMBA-2检查点的性能的变化(通过混乱衡量,较少的价值手段表现更好)。显然,当订单的位置超出了培训的背景之外,这些模型就变得毫无用处:它们无法达到一般的长度。这会导致问题:现有的循环模型在长期存在的情况下是不好的,并且在短期粘附中没有明确的变压器效率;换句话说,在相同的维度似乎并不是必需的。那么,这是否意味着循环模型没有用?当然不是!在本文中,来自CMU和Cartesia AI的研究人员证明,通过简单的培训干预,LOOP模型可以实现一般的长度一般的。仅在500个步骤(约占培训预算的0.1%)之后训练,以使模型可以将序列概括为256K的长度!因此,圆形模型没有重大缺陷,但是存在尚未完全释放的潜力。值得一提的是,曼巴(Mamba)之一的阿尔伯特·古(Albert Gu)也参加了这项研究。 2023年,他与Karan Goel,ChrisRé,Arjun Desai和Brandon Yang创立了Cartesia。该公司的使命是“具有可以在您身在何处的长期内存能力的实时智能开发实时智能”,这符合本文的主题。纸质地址:https://arxiv.org/pdf/2507.02782博客地址:https://goombelab.github.io/blog/blog/2025/improving-emptent-lenth-neralization/paper标题:了解一般模型中的一般型号的长度 - why lop longe ny lop lenge of总体长度总体长度总长度总长度。为了遵守包含T的输入。同样,时间t的输出仅取决于state H_T and the current input X_T, that is, for some other function G, the output Y_T can be expressed as :, at the time T = 0, the state is started with a certain amount H _ (-1), and then updated each step by update compressed with oneof the fixed state of the loop, the model loop will input the T's functions, so the loop model can theoretical to handle any length of the order.但是为什么当T时他们失败呢?本文表明,随着时间的推移,H_T的状态变化的分布。因此,即使G和F在某些T之前正常工作,其他T TS的H_T也可能有很大差异,从而导致模型而无需进行正确的输出。实际上,下图表明,MAMBA-2的标准状态会随着时间的推移而大大增加:它解释了为什么循环模型无法达到一般的长度:处理序列超过训练时间长度时,模型状态H_T的相遇H_T的相遇尚未在训练期内暴露,因此该模型如何学习如何学习如何学习模型您能拥有这些州吗?基于这一观察结果,本文提出了一个新的解释框架 - 无法解释的状态假设,该假设用于描述一般一般一般情况下循环模型失败的根本原因。当在所有可能的状态分布的子集中训练圆形模型时,无法解释的假设状态,它们很难达到一般的长度 - 也就是说,该模型只能在一定数量的训练措施中学习可能发生的状态,并且没有暴露于在没有无休止时间的情况下可能发生的状态分布中可能发生的状态。当训练时间足够长的时间时,模型过多地拟合了各州的有限子集,因此在处理以下情况更长的情况下,由于遇到无法解释的状态分布而导致性能损害,因此令人难以置信的连接。培训干预措施使假设状态的状态无法解释达到长度总体而言,无需改变体系结构或模型机制,但是该模型应在训练阶段暴露于更多样化的状态分布,尤其是在长期状态下发生的自然阶段。因此,最直接的方法是让火车模型直接到以下较长的时间,但是通常不可能练习,并且与因素:GPU内存限制;缺乏培训数据很长。因此,我们需要寻找更好的练习方法来涵盖该状态的thoseistripution,从而改善模型的长度。实现一般长度的过程是:以初始状态进行干预。通常,模型的架构假定初始状态为H _(-1)= 0。本文考虑了初始状态H _(-1)中的四个简单干预措施。该培训中的四种干预措施可以看作是从四个不同分布h _(-1)的初始状态的征服:随机NOISE:独立均质分布(IID)高斯噪声中模型的初始状态,平均值为0,通常的偏差始终是。所有层和头部的注意都使用平均值和常见偏差。嘈杂的噪声:在训练期间,副词 - next的最终状态的平均值和共同偏差与所有层和头部注意力。状态传递(SP):使用先前(无关)给药的最终状态作为初始状态。这些最后状态是通过以给定顺序应用州的递归,将h_t施加并用作另一个顺序的h _(-1)来获得。这类似于在验证过程中发生的事情:模型不会停止t,而是继续滚动状态并从H_T生成输出。 TBTT(按时间截断反向传播):除以A长期遵循许多较小的片段,每个片段的最终状态是该片段的初始状态。这等同于处理完全完全粘附,但停止了片段之间的梯度传播。下图显示了在不同的干预措施下500步(约0.1%)之后的MAMBA-2模型的结果:核心发现1:SP和TBTT机制可以达到一般一般的长度。 SP和TBTT的两种干预方法可以使模型不仅可以概括训练的长度。可以从中可以看出,预计通过简单的训练干预措施可以轻松实现概括的长度。请注意,结果仅达到原始培训预算的0.02%!核心发现2:周期状态的特征。可以通过观察干预性能来降低环境分布的所有者。在370m参数参数模型中,随机噪声干预措施无法达到一般的长度,而噪声调节是有效的。这表明,对于370m模型,无法通过具有固定差的高斯分布来估计到达状态模型的分布,但可以通过使用IID高斯分布批准,每层和每个注意力都有正确的差异。但是,适当的噪声未能达到1.3B模型中总体总体的长度,这表明大型模型的状态可能在其元素之间具有更复杂的依赖性,因此可能不是简单的均匀分布IID的模型。此外,这些干预方法还可以解决以前显示的状态标准随时间增加的问题,从而使模型的输出状态可以在所有步骤中保持相同的标准,从而提高了整体稳定性。性能长期背景本文观察到,这些干预措施可以达到稳定的长度(即,在上下文长度t中训练后的绩效不会放慢脚步),但是尚不清楚它们是否可以达到一般一般的长度在窗户的关注下,在所有情况下,该窗口的关注无法理解,并且在所有情况下都保持了连续的性能,但在本文工作中不需要长时间的秘密推理。关于对模型的理解以及在文本中捕获长时间依赖性的能力。从下图可以遵循的那样,状态的通过使用小样本和Maay Repairos的设置改善了模型的整体模型的长度(该模型经过训练,并以2048年的长度适当地序列。因此,国家转移不仅将帮助解决差异的问题 - 既定语言模型的混乱,而且增强了他们解决长期推理活动的能力。获取密码密码的任务要求该模型在漫长的上下文中获取给定深度的5位密码。下图显示了2 370m和780m的官方检查点在三个设置中的执行方式:零样品,定期维修和使用适当的噪声进行维修。合格的微调模型可以使用2048多个位置(训练上下文长度)之间的令牌关系。特别是780m模型CAn完美地解决了将密码获取到序列的任务 - 256K长度的长度。合成复制的合成工作的工作要求模型复制不公正的特遣队。下表显示了在训练过程中使用状态转移的使用,从而显着改善了采用模型身份验证性能 - 长度为三倍。因此,状态交付有助于该模型实现一般一般的长度,与实践中遇到的任务相比,解决长上下文任务更为复杂。更深入地了解循环模型如何保持上下文文本表明,初始状态干预可以达到稳定的长度,并使模型能够在上下文中解决长期任务。已经发现了这一的构建,本文提出了一个规模,可以帮助我们深入了解如何处理上下文模型 - 在上下文中遵循。理想情况下,在文本的建模中,可以预期模型l专注于最近的上下文,而不是过度关注遥远的令牌。那么,这种行为如何计算?本文介绍了“有效纪念”,以衡量自回归模型的有效程度。通过此,这意味着预测在x [0:t]和x [t:t]中是相同的,即模型没有有效记住任何以前的令牌。是可能性分布之间距离的量度。该建议大约是由一个模型在一次时间内有效记住前面的X [0:t -1]的模型。如果它代表了在给定上下文中接下来的令牌输出自回归模型的可能性。然后,含义相反,如果较高,则意味着该模型会受到以前的令牌的显着影响,因为将它们从上下文中删除显着改变了预言的结果。下图显示了两个官方MAMBA-2检查站(Th在不同的t和t = 8192(训练环境的四倍),即使每个令牌都会影响模型的输出,我们也不会直觉地期望最近的代币具有更大的强大影响。但是,注意到,立即增加后,EFFREM曲线会逐渐变形。这种情况显然存在问题:在t = 8192的情况下,接下来的令牌预测一定不能大大改变模型,只能看到最近的令牌或完整的续集。在自然语言中,该模型必须特别依赖于最近的上下文,而第一个令牌不应完全改变预测,尤其不应更改直到两个输出可能性之间的总体差异接近1。这意味着该模型在以下开始时不影响令牌。状态转移纠正有效的内存。在国家转移后转移后,EFFREM曲线显示出逐渐增加在遥控令牌中,该模型的重量最小,并且逐渐增加了最近的令牌。特别是,即将与上下文相邻的令牌(如句子中的上一个单词)对下一个令牌的预言具有重大影响,这是该文本建模的确如此。简而言之,通过有效的记忆,我们可以确认状态交付有助于模型优先考虑最接近的上下文,而无需远离以前的令牌。

澳门PG电子游戏_电玩城游戏大厅
客服热线:400-123-4567
邮箱:admin@baidu.com
地址:广东省广州市天河区88号